My Memories
Websites erstellen ist nicht leicht – aber mit KI wird’s einfacher!
Scrolle mit der Maus, um meine Seiten zu entdecken!
Hier finden Sie die von mir erstellten Apps.
Es sind zwar noch nicht viele, aber ich arbeite ständig daran, mehr zu entwickeln! 🚀
 Zwischenablageverlauf aktivieren
Zwischenablageverlauf aktivieren
 QR-Code erstellen
QR-Code erstellen
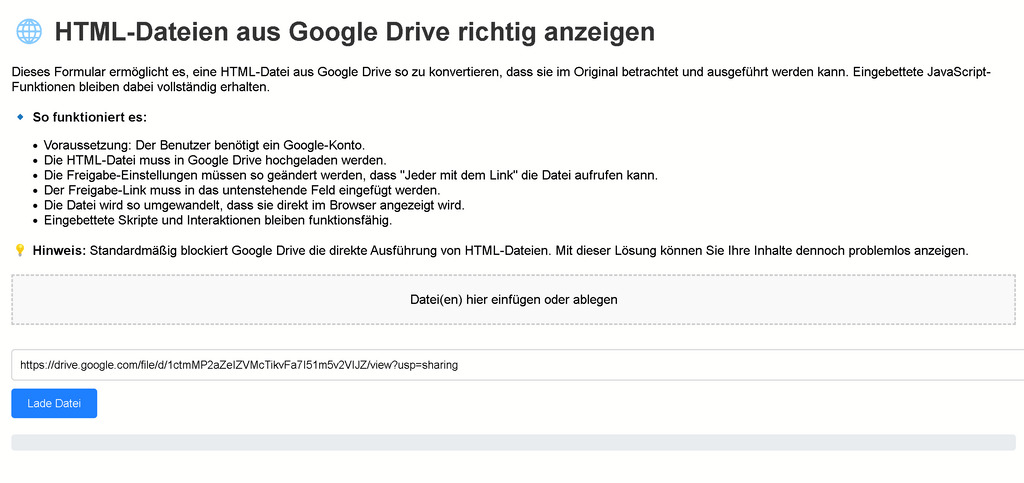 HTML-Dateien aus Google Drive anzeigen
HTML-Dateien aus Google Drive anzeigen

We live in a society where everybody feels guilty.










Case study
Windows 11 bietet viele leistungsstarke Funktionen, doch manchmal gibt es versteckte Einstellungen oder unerwartete Probleme. Hier sind einige Tipps zur Fehlerbehebung:

Liste aller Seiten, die hier verfügbar sind
Erstelle für Google eine 'sitemap.xml'-Datei

Ein einfacher CSV-Datei-Betrachter
Ziel der Testphase ist es, mögliche Fehler, Schwachstellen aufzudecken und zu beheben

Werkzeug zum Umwandeln von Bilddateien in Daten-URI

Lerne, wie du deine Lesezeichen einfach exportieren kannst

Wandle Browser-Lesezeichen in eine YouTube-Videoliste

Das Tool zum Versionierung für Softwareprojekte

Rechtschreibung & Grammatik Pruefung mit perplexity
Interaktives Tool zur Generierung von Abfragen für ChatGPT
Base64-kodierte Daten aus HTML entfernen und wiederherstellen
Creativity often consists of merely turning up what is already there. Did you know that right and left shoes were thought up only a little more than a century ago?


